Kafka가 뭐야?
Apache Kafka의 기본 개념과 아키텍처 정리
 Apache Kafka
Apache Kafka
카프카(Kafka)란?
Kafka는 Pub-Sub 모델의 메시지 큐예요. 분산 환경에 특화되어 있습니다.
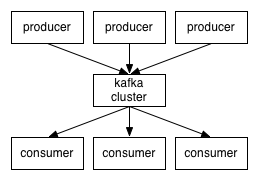 Kafka 기본 아키텍처
Kafka 기본 아키텍처
카프카 클러스터를 중심으로 Producer와 Consumer가 데이터를 Push하고 Pull하는 구조죠.
구성요소
Event: Producer와 Consumer가 데이터를 주고받는 단위입니다.
Producer: Kafka에 메시지를 게시하는 클라이언트 애플리케이션입니다.
Broker: 카프카 서버를 말합니다.
Zookeeper: 분산 코디네이션 시스템이에요. Kafka Broker를 하나의 클러스터로 묶어주는 역할을 합니다.
Topic: 메시지가 쓰이는 곳이에요. Producer는 Topic에 메시지를 게시하고, Consumer는 Topic에서 메시지를 가져와 처리합니다. 하나의 Topic은 1개 이상의 Partition으로 구성돼요.
Partition: Topic이 여러 Broker에 분산되어 저장되는데, 이렇게 분산된 Topic을 Partition이라고 해요. 같은 키를 가지는 메시지는 항상 같은 Partition에 저장됩니다.
Consumer: Topic을 구독하고 메시지를 처리하는 클라이언트 애플리케이션입니다.
주요 개념
Producer와 Consumer의 분리
Kafka의 Producer와 Consumer는 완전 별개로 동작합니다. Producer는 Broker의 Topic에 메시지를 게시하기만 하면 되며, Consumer는 Broker의 특정 Topic에서 메시지를 가져와 처리하기만 하면 됩니다.
이 덕분에 Kafka는 높은 확장성을 제공해요. Producer나 Consumer를 필요에 따라 Scale In/Out 하기 용이한 구조입니다.
Push와 Pull 모델
Kafka의 Consumer는 Pull 모델 기반으로 메시지를 처리해요. Broker가 Consumer에게 메시지를 전달하는 게 아니라, Consumer가 필요할 때 Broker에서 메시지를 가져와 처리하는 형태입니다.
다양한 소비자의 처리 속도를 고려하지 않아도 되고, 불필요한 지연 없이 일괄처리를 통해 성능을 향상시킬 수 있습니다.
Commit과 Offset
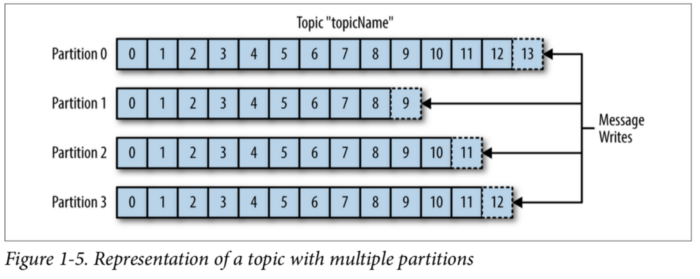 Kafka Partition과 Offset 구조
Kafka Partition과 Offset 구조
메시지는 로그에 순차적으로 append 됩니다. 메시지의 상대적인 위치를 offset이라고 칭합니다.
Consumer의 poll()은 이전에 commit한 offset 이후의 메시지를 읽어오게 됩니다. 읽어온 뒤 마지막 offset을 commit합니다.
Consumer는 멱등성을 고려하여야 합니다. 같은 메시지를 여러 번 받아서 여러 번 처리하더라도 한번 처리한 것과 같은 결과를 가지도록 설계해야 합니다.
Consumer Group
Consumer Group은 하나의 Topic을 구독하는 Consumer 모임이에요. 가용성을 위해 필요합니다.
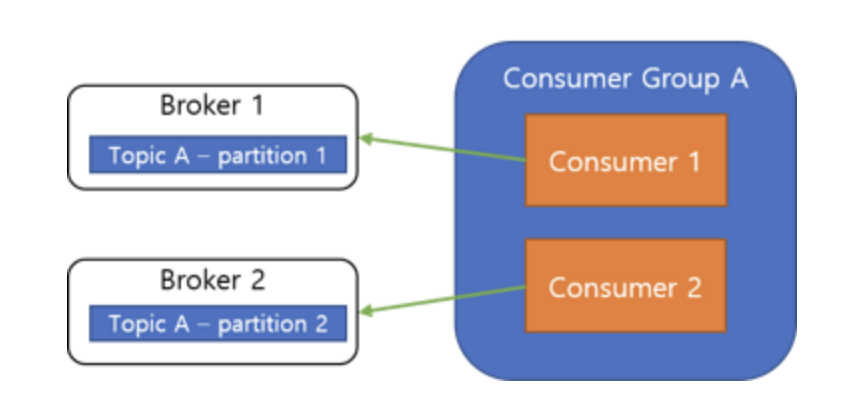 올바른 Consumer Group과 Partition 관계
올바른 Consumer Group과 Partition 관계
Consumer Group 내 Consumer는 각기 다른 Partition에 연결되어야 해요. 이렇게 해야 메시지 처리 순서를 보장할 수 있습니다.
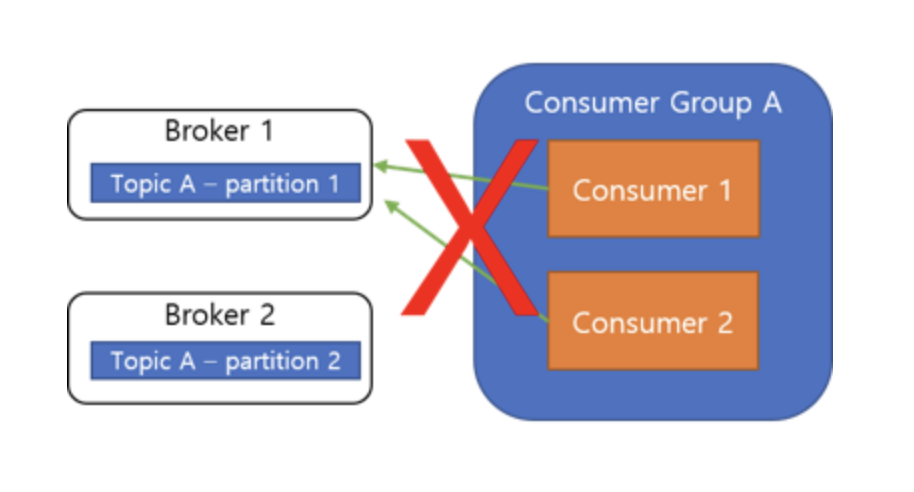 잘못된 Consumer Group과 Partition 관계
잘못된 Consumer Group과 Partition 관계
하나의 Partition은 하나의 Consumer에만 할당될 수 있습니다.
Rebalance: Partition을 담당하던 Consumer가 죽으면, Partition과 Consumer를 재조정해서 남은 Consumer가 Partition을 나눠 처리해요.
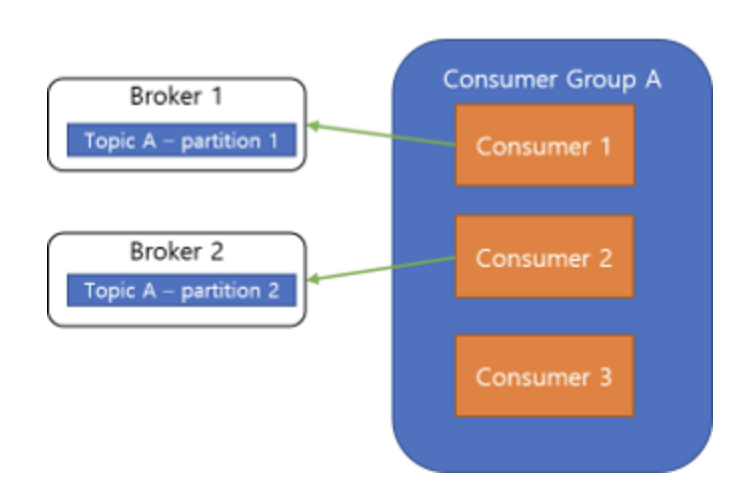 비효율적인 Consumer 확장
비효율적인 Consumer 확장
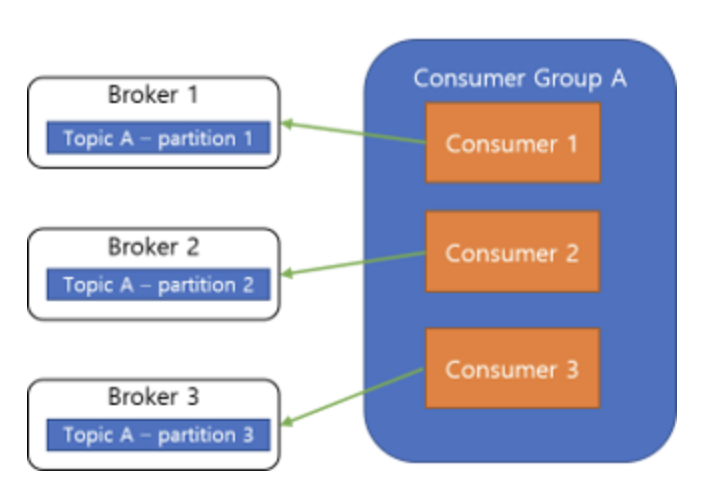 효율적인 Consumer 확장
효율적인 Consumer 확장
Consumer를 확장할 때는 Partition도 같이 늘려주어야 합니다. Partition보다 Consumer의 수가 많으면 새 Consumer는 놀게 됩니다.
메시지 전달 방식
At most once: 실패나 타임아웃이 발생하면 메시지를 버릴 수 있어요.
At least once: 메시지가 최소 1번 이상 전달되는 걸 보장합니다. 동일한 메시지가 중복으로 처리될 수 있어요.
Exactly once: 메시지가 정확히 한 번만 전달되는 걸 보장해요. 구현 난이도가 높고 비용도 많이 듭니다.
더 자세한 내용은 Kafka 공식 문서를 참고하세요.